OpenAI 放大招“对打”谷歌 Gemini:全力筹备多模态大模型,并发布新指令语言模型
发布时间:2023-09-21 15:26:31
面对挑战,OpenAI 连续放大招,除了发布新指令语言模型 GPT-3.5-turbo-instruct,还计划推出多模态大模型 GPT-Vision 与 Gobi。据一位未公开身份的知情人士透露,OpenAI 在积极将多模态功能(类似于 Gemini 将要提供的功能)纳入 GPT-4。
新语言模型 InstructGPT-3.5
近日,OpenAI 推出 GPT-3.5-turbo-instruct,这是一款新的指令语言模型,效率可以与聊天优化的 GPT-3.5 Turbo 模型相媲美。
指令模型属于大语言模型的一种,会在使用一大量数据进行预训练之后,再通过人类反馈(RLHF)做进一步完善。在此过程中,会由人类负责评估模型根据用户提示词生成的输出,对结果做改进以达成目标效果,再将更新后的素材用于进一步训练。
因此,指令模型能够更好地理解并响应人类的查询预期,减少错误并缓解有害内容的传播。从 OpenAI 的测试结果来看,尽管体量仅为后者的百分之一,但人们明显更喜欢拥有 13 亿参数的 InstructGPT 模型,而非拥有 1750 亿参数的 GPT 模型。
据了解,GPT-3.5-turbo-instruct 的成本与性能同其他具有 4K 上下文窗口的 GPT-3.5 模型相同,使用的训练数据截止于 2021 年 9 月。

GPT-3.5-turbo-instruct 将取代一系列现有 Instruct 模型,外加 text-ada-001、text-babbage-001 和 text-curie-001。这三款 text-davinci 模型将于 2024 年 1 月 4 日正式停用。
OpenAI 表示,GPT-3.5-turbo-instruct 的训练方式与之前的其他 Instruct 模型类似。该公司并未提供新 Instruct 模型的细节或基准,而是参考了 2022 年 1 月发布的 InstructGPT,即 GPT-3.5 模型的实现基础。
OpenAI 称,GPT-4 拥有超越 GPT-3.5 的复杂指令遵循能力,生成的结果也比 GPT-3.5 质量更高;但 GPT-3.5 也有自己的独特优势,例如速度更快且运行成本更低。GPT-3.5-turbo-instruct 并非聊天模型,这一点与原始 GPT-3.5 有所区别。具体来讲,与之前的聊天应用模型不同,GPT-3.5-turbo-instruct 主要针对直接问答或文本补全进行优化。
速度方面,OpenAI 称 GPT-3.5-turbo-instruct 速度与 GPT-3.5-turbo 基本相当。
下图为 OpenAI 设计的 Instruct 指令模型与 Chat 聊天模型之间的区别。这种固有差异自然会对提示词的具体编写产生影响。
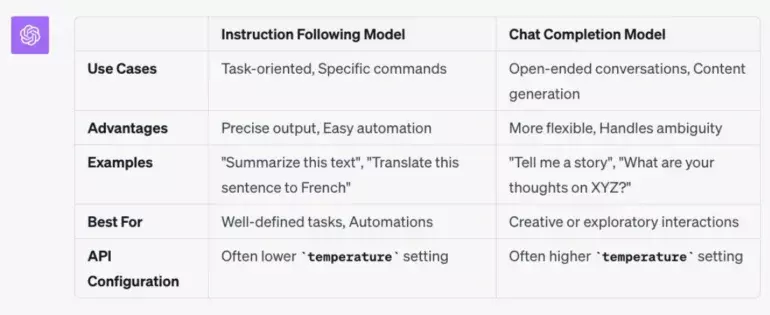
OpenAI 负责开发者关系的 Logan Kilpatrick 称,这套新的指令模型属于向 GPT-3.5-turbo 迁移当中的过渡性产物。他表示其并不属于“长期解决方案”。已经在使用微调模型的用户,需要根据新的模型版本做重新微调。目前微调功能只适用于 GPT-3.5,GPT-4 的微调选项计划于今年晚些时候发布。
多模态大模型 GPT-Vision 与 Gobi
除了 GPT-3.5-turbo-instruct,OpenAI 近日还计划发布多模态大模型 GPT-Vision,以及一个代号为“Gobi”的更强大的多模态大模型。
据悉,GPT-Vision 在 3 月份的 GPT-4 发布期间首次预览,是 OpenAI 融合文本和视觉领域的雄心勃勃的尝试。虽然该功能最初实际用例仅限于 Be My Eyes 公司,这家公司通过其移动应用帮助视力障碍或失明用户进行日常活动。
GPT-Vision 有潜力重新定义创意内容生成的界限。想象一下使用简单的文本提示生成独特的艺术品、徽标或模因。或者考虑一下对有视觉障碍的用户的好处,他们可以通过自然语言查询与视觉内容交互并理解视觉内容。该技术还有望彻底改变视觉学习和教育,使用户能够通过视觉示例学习新概念。
如今,OpenAI 正准备将这项名为 GPT-Vision 的功能开放给更广泛的市场受众。
此外,据 The Information 报道,OpenAI 即将发布代号为“Gobi”的下一代多模态大语言模型,希望借此击败谷歌并继续保持市场领先地位。目前,Gobi 的训练还没有开始,有评论认为其有机会成为 GPT-5。
报道称,OpenAI 之所以耗费大量时间来推出 Gobi,主要是担心新的视觉功能会被坏人利用,例如通过自动解决验证码来冒充人类,或者通过人脸识别追踪人们。但现在,OpenAI 的工程师们似乎想到办法来缓解这个安全问题了。
OpenAI CEO:GPT-5 尚未出现,计划将多模态功能纳入 GPT-4
据了解,多模态大语言模型的本质是一种先进 AI 系统,能够理解和处理多种数据形式,包括文本和图像。与主要处理文本内容的传统语言模型不同,多模态大语言模型能够同时对文本加视觉类内容进行分析和生成。
也就是说,这类模型可以解释图像、理解上下文并生成包含文本和视觉输入的响应结果。多模态大模型还拥有极高的通用性,适用于从自然语言理解到图像解释的诸多应用,借此提供更广泛的信息处理能力。
报道指出,“这些模型能够处理图像和文本,例如通过查看用户绘制的网站外观草图来生成网站构建代码,或者根据文本分析结果输出可视化图表。如此一来,普通用户也能快速理解内容含义,不必再向拥有技术背景的工程师们求助。”
OpenAI 首席执行官 Sam Altman 在最近的采访中表示,尽管 GPT-5 尚未出现,但他们正计划对 GPT-4 进行各种增强。而开放多模态支持功能,也许就是这项计划的一部分。
在上周接受《连线》采访时,谷歌 CEO 桑达尔·皮查伊表达了他对于谷歌当前 AI 江湖地位的信心,强调其仍掌握着技术领先优势、并在创新与责任方面求取平衡的审慎战略。他也对 OpenAI ChatGPT 的深远意义表示认可,称赞其拥有良好的产品-市场契合度、让用户对 AI 技术做好了准备。但他同时强调,谷歌在产品信任和负责态度方面会采取更加谨慎的立场。







